Updated at 22/11/12 啊,半年过去了,我也上中学了,过的好快啊。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 import requestsimport jsonimport jsonpathimport osfrom tqdm import tqdmint (input ("1.歌单 2.歌曲 >> " ))if choose == 1 :input ('请输入歌单网址: >>>' )int (playlist_url.strip().split('=' )[1 ].split('&' )[0 ])'https://api.injahow.cn/meting/?type=playlist&id={}' .format (playlist_id)for i in data:'$..url' )0 ])'$..name' )[0 ].replace('/s*/g' , "" ))print ('总共有{}个链接,开始下载……\n' .format (len (urls)))input ("自行命名文件夹名(不填即为歌单ID):" )if dir_name == '' :'.\\dmusic\\playlist\\{}\\' .format (dir_name), exist_ok=True )for url in tqdm(urls, desc='下载中' ):with requests.get(url) as resp:with open ('.\\dmusic\\playlist\\{}\\' .format (dir_name) + str (names[0 ]) + '.mp3' ,'wb' ,as f:0 )print (f'下载成功,请在 .\\dmusic\\playlist\\{dir_name} 文件夹中查看您的音乐' )elif choose == 2 :input ('请输入歌曲网址 (q退出): >>>' )int (song_url.strip().split('=' )[1 ].split('&' )[0 ])while song_url != 'q' :'https://api.injahow.cn/meting/?type=song&id={}' .format (song_id)0 ], '$..name' )[0 ].replace('/s*/g' , "" )'.\\dmusic\\song\\' , exist_ok=True )with requests.get(url=jsonpath.jsonpath(data, '$..url' )[0 ]) as resp:with open ('.\\dmusic\\song\\' + str (song_name) + '.mp3' ,'wb' ,as f:print (str (song_name) + "下载成功" )input ('请输入歌曲网址 (q退出): >>>' )
算是大更新吧,攻克一道难关。也许这是最后的版本了。https://pan.nikoblog.top/api/raw/?path=/音乐歌单/下载音乐.exe
TO DO LIST:
Updated at 22/06/18 今天新的读卡器到了,给音响里加几首歌,急需歌曲单首下载,加了点功能。
嘿,大家好,今天复习了一下爬虫知识,自己想爬个网易云的歌单下来,备着以后禁网的时候听。但由于我懒癌晚期,懒得直接上浏览器上搜,搜着,发现没有一个合格的。
没办法,只能自己写了。就是套了个api嘛。源码如下。
只有进度条版本的。。。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 import requestsimport jsonimport jsonpathimport osfrom tqdm import tqdmint (input ("1.歌单 2.歌曲" ))if choose == 1 :input ('请输入歌单网址: >>>' )int (playlist_url.strip().split('=' )[-1 ])'https://api.injahow.cn/meting/?type=playlist&id={}' .format (playlist_id)for i in data:'$..url' )0 ])print ('总共有{}个链接,开始下载……\n' .format (len (urls)))'.\\dmusic\\playlist\\{}\\' .format (playlist_id),exist_ok=True )for url in tqdm(urls, desc='下载中' ):'=' )[-1 ]with requests.get(url) as resp:with open ('.\\dmusic\\playlist\\{}\\' .format (playlist_id) + str (song_id) + '.mp3' ,'wb' ,as f:elif choose == 2 :input ('请输入歌曲网址 (q退出): >>>' )while song_url != 'q' :int (song_url.strip().split('=' )[-1 ])'https://api.injahow.cn/meting/?type=song&id={}' .format (song_id)'.\\dmusic\\song\\' ,exist_ok=True )with requests.get(url=jsonpath.jsonpath(data, '$..url' )[0 ]) as resp:with open ('.\\dmusic\\song\\' + str (song_id) + '.mp3' ,'wb' ,as f:print (str (song_id) + "下载成功" )input ('请输入歌曲网址 (q退出): >>>' )
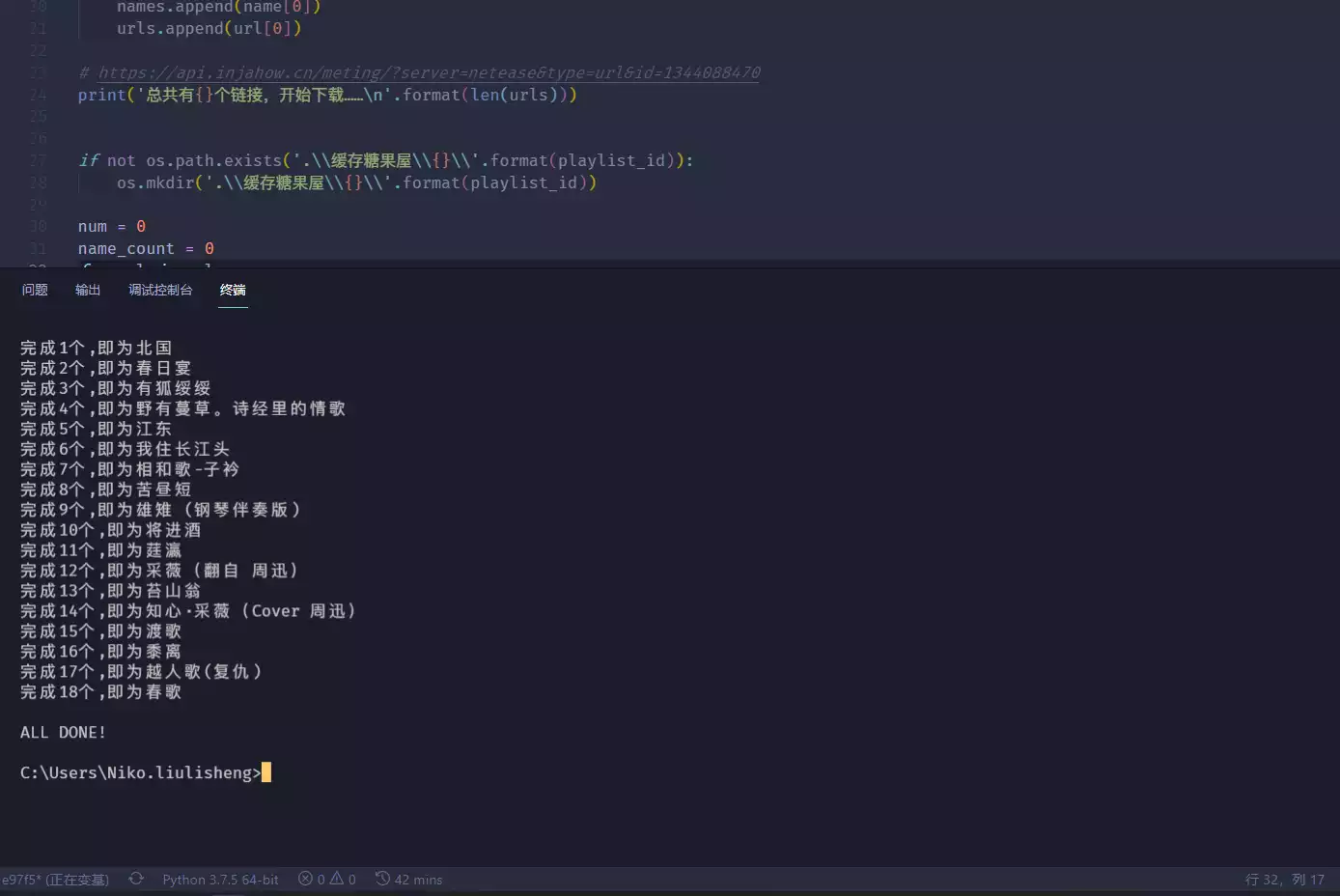
效果:
如果看到那些用ID命名的歌曲不惯呢,可以打开网易云音乐桌面版 –> 打开本地音乐 –> 选择目录 –> 把缓存糖果屋添加进去 –> 添加完后,点击匹配音乐 –> ALL DONE!